
关于 istio-proxy 503/504等5xx问题排查
问题描述
在生产环境,我们最近部署了Istio Service Mesh,Istio控制平面会在每个服务Pod里自动注入一个sidecar。当各个服务都初始化istio-proxy,通过sidecar去实现服务间的调用时,应用和服务就会面临一个很普遍的问题:upstream 服务调用收到HTTP 503/504 response,这个报错信息通常都是由istio-proxy产生的。HTTP 503通常发生在应用和istio-proxy的inbound或者outbound调用,或者是服务网格外部的服务调用。影响面相对严重的是通过网格访问外部服务的outbound流量,相对小的是网格内部的inbound流量。HTTP 504的问题相对要少一些,只有在upstream service的接口response时间超过15秒时才会发生,因为istio-proxy的默认response超时时间就是15秒。
 这个问题的现象跟真实的upstream组件失败错误很相似,然而,通过现象分析也有可能是istio本身的默认配置对于网格内部的应用不是那么健壮而问题引起的,对于那些影响面比较大的outbound服务调用:在某一个时间周期内,会有大量的503发生(通常访问量越大报错越多),过一段时间后自己会自愈,周而复始。
这个问题的现象跟真实的upstream组件失败错误很相似,然而,通过现象分析也有可能是istio本身的默认配置对于网格内部的应用不是那么健壮而问题引起的,对于那些影响面比较大的outbound服务调用:在某一个时间周期内,会有大量的503发生(通常访问量越大报错越多),过一段时间后自己会自愈,周而复始。
影响小一些的inbound调用,在应用监控面板上看不到报错信息,只有在istio-proxy的log里会发现一些503的痕迹,因为我们通常会在客户端或者上游调用时配置重试规则,大部分异常调用都会在重试后成功拿到数据。
对于outbound调用,504 response timeout错误只会对组件依赖超过15秒的请求造成影响。 可以观察一下istio-proxy日志里的HTTP 503/504 upstream错误,进一步的关于日志格式和response flags的信息可以点击链接查看。envoy log
在详细探究这个错误的具体原因之前,我们先看一些错误一日信息的示例: Inbound Call Error example
下面是一个istio-proxy日志里到达请求的response flag “UC”异常日志,含义是:“Upstream connection termination in addition to 503 response code”,由于某种原因在同一个pod里的istio-proxy和他的upstream容器之间的链接被断开了。
还有另外一种response flag “UF”异常日志, 含义是:“Upstream connection failure in addition to 503 response code”,由于某种原因使同一个pod内的istio-proxy和他的upstream容器没办法建立链接
[2022-04-18T09:29:59.633Z] "GET /service_a/v2.1/get?ids=123456 HTTP/1.1" 503 UC "-" "-" 0 95 11 - "-" "-" "bc6f9ba3-d8dc-4955-a092-64617d9277c8" "srv-a.xyz" "127.0.0.1:8080" inbound|80|http|srv-a.xyz.svc.cluster.local - 100.64.121.11:8080 100.64.254.9:35174 -
[2022-04-18T08:38:43.976Z] "GET /service_b/v2.5/get?getIds=123456 HTTP/1.1" 503 UF "-" "-" 0 91 0 - "-" "-" "d0dbd0fe-90db-46d0-b614-7eaea3764f79" "srv-b.xyz.svc.cluster.local" "127.0.0.1:8080" inbound|80|http|srv-b.xyz.svc.cluster.local - 100.65.130.7:8080 100.64.187.3:53378 -
Outbound Call Error example
下面是一条访问外部服务时记录在istio-proxy日志里response flag “UF”的错误信息,HTTP状态码为503,含义是:“Upstream connection failure in addition to 503 response code“,这个错误跟上面一条有些类似,是由于某些原因没办法同外部host建立连接。
[2022-04-18T17:27:02.903Z] "GET /External.WebService/v2/Ids HTTP/1.1" 503 UF "-" "-" 0 91 0 - "-" "Apache-HttpClient/4.5.5 (Java/11)" "c75a750d-9efd-49e7-a419-6ed97298b543" "external.service.com" "55.92.142.17:80" PassthroughCluster - 55.92.142.17:80 100.65.254.14:39140 -
接下来在看一下由于upstream response timeout引起的response flag “UT”HTTP 504的异常问题,“Upstream request timeout in addition to 504 response code“,这时istio-proxy 等待了15000毫秒,直到连接断开。
[2022-04-18T07:18:17.609Z] "POST /ext_svc/1111000222333/add?currency=GBP&locale=en_GB HTTP/1.1" 504 UT "-" "-" 150 24 15004 - "-" "Jersey/2.27 (HttpUrlConnection 11.0.4)" "7e9a9207-690f-45b1-b574-fc806b117a84" "testservice.prod.com" "10.186.199.78:80" PassthroughCluster - 10.186.199.78:80 100.65.161.7:37302 -
[2022-04-18T23:05:06.499Z] "GET /api/1234567 HTTP/1.1" 504 UT "-" "-" 0 24 15001 - "-" "ABC.3.1.449" "4403f657-f324-4c60-befd-343a23e9520a" "apisvc.prod.com" "10.186.199.78:80" PassthroughCluster - 10.186.199.78:80 100.66.91.11:50288 -
问题产生的原因
Inbound 调用
所有应用的inbound调用都会被istio-proxy通过iptables规则劫持,无论是inbound或者是outbound流量,istio-proxy都会通过localhost的15001端口同应用容器建立一个新的链接。由于istio-proxy提供的是L7代理,需要通过在集群内各个pod直接维持的长链接实现请求负载均衡。问题就来了,由于在K8S内部默认的TCP L4链接负载均衡的限制,应用服务器例如Tomcat和Finagle在回收应用链接时都有maxKeepAliveRequests和MaxLifeTime的参数设置,链接维持一段时间之后都会在服务了一定数量的请求或者经过一个固定时间周期后被回收。
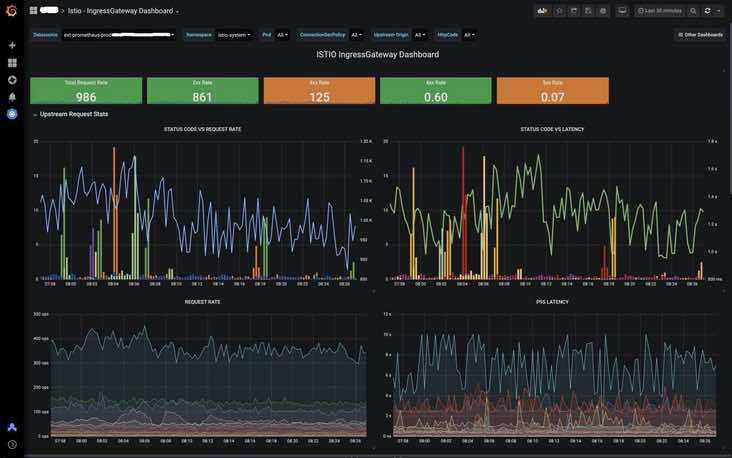
在下图中,红色箭头表示的链接被应用服务器终止了,但是istio-proxy仍然在为另一个请求复用这个链接,此时这个upstream链接就会收到503 error code (response flag UC),这个问题在高并发场景就相对比较常见。
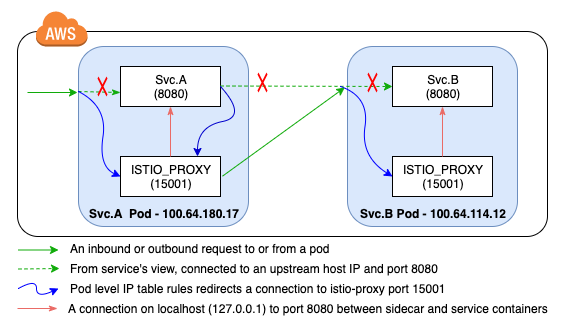
inbound请求还有另外一种503错误,response flag为 UF (upstream connection failure),这通常是由于应用容器自己crash掉了引起的。
outbound调用
在标准的istio网格环境里,一个请求通过istio-proxy请求一个外部服务,如果没有为这个外部服务设置详细的Istio配置(例如ServiceEntry),那么就不会有路由或者流量管理规则可以被使用,它就是一个简单的维持在目标服务之间的HTTP1.1协议的TCP链接。正在初始化outbound请求的应用在离开本地网络接口之前需要解析外部域名的DNS协议,IPtable规则劫持这个请求并转发到istio-proxy,然后istio-proxy会关闭这个链接并开启一个执行远端主机IP的新链接。
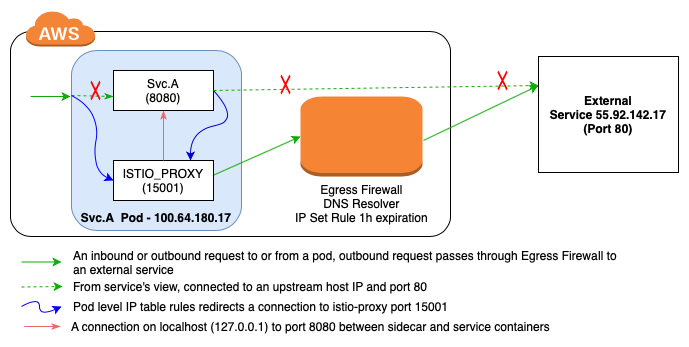
istio-proxy不会主动关闭这个长链接,除非启动该链接的应用想要主动关闭它。因此,该应用发起的新请求不会再进行DNS解析,因为从应用视角来看已经建立了链接。随着时间流逝,istio-proxy将会返回一个503错误。
具体原因: 1、通过安全组件访问外部服务 如果通过安全组件(egress防火墙)实现内部网络到外部服务的网络调用,当一个DNS请求到来时将会做以下两件事:(1)同白名单列表进行比对,检查这个外部服务是否被允许访问。(2)如果被允许访问,安全组件将会把模板IP添加到IPSET,默认过期时间是3600秒,防火墙host IPSET样例如下:
[ec2-user@egress-proxy-4 ~]$ ipset list | grep external
55.92.142.17,tcp:80 timeout 3697 comment "external.service.com."
55.92.142.17,tcp:443 timeout 3697 comment "external.service.com."
一单上述规则超期,对于那些istio-proxy 使用相同IP发起而没有DNS解析的新请求将收到如下错误:“upstream connect error or disconnect/reset before headers. reset reason: connection failureHTTP/1.1 503” 。这个原因引发的异常,如果有其他应用访问相同的外部服务,而且恰好是第一次发起请求,IPSET规则将会被更新,当前应用的503异常将会自愈。
1、外部服务的Host是云服务ELB提供的动态IP 这种情况,503错误是比较罕见地,因为Host IP不会比集群内组件部署更频繁的发生变化。但是当ELB更新时,istio-proxy使用长链接访问外部IP时依然会产生503错误。
可能的解决方案
inbound调用
在理想状况下,同一pod内的istio-proxy应该能够捕捉到上游应用服务器的上游链接断开事件。然而在istio后续版本设计解决这个问题之前,有一个简单的变通办法可以解决这个问题:对于inbound调用,针对链接,设置一个无限的请求管道,只需要超时时间用来处理链接回收。
for Tomcat app server
maxKeepAliveRequests = -1
for Finagle app server
# Don't set any value, then it defaults to unbounded.
maxLifeTime(timeout: Duration)
在K8S集群内部,集群内的请求是通过ServiceIp实现的,ServiceIp是通过L3/L4实现的,仅仅实现了链接的负载均衡。因此,它需要在服务一定数量的请求之后关闭这些链接,以便正确的、均衡的分发请求到后端多个实例。尽管频繁的关闭链接会影响延迟,但是与跨实例的请求负载不均衡相比,这是非常必要的,因为这将引起某些实例负载过高。通过Istio,不需要回收链接,因为istio-proxy工作在7层,通过长链接来实现的请求负载均衡,只有空闲时间超时之后才会去关闭链接,客户端和服务端都需要实现空闲链接的清理工作。
outbound调用
现在我们知道了使用istio-proxy outbound调用产生503的错误原因,需要为外部服务主机周期性的进行DNS解析。下面这些选项可能会对解决问题提供帮助 (1)outbound调动尽量不要使用长链接– 虽然能解决问题,但是如果服务的QPS很高,这将影响扩展性。 (2)定期进行DNS解析– 修改应用代码去定期关闭链接并重新开发一个链接以便更新DNS解析,可以解决问题,但是需要修改代码。 (3)配置istio定期进行DNS解析–这是最好的解决方案,不需要修改应用代码而且还部署简单。istio流量规则允许为一个外部请求配置一个 ServiceEntry 和VirtualService,通过配置这些规则可以避免503问题。 (4)配置istio增加超时时间–为了避免504response超时问题和适应上游服务调用的response 超时时间长于15秒,配置VirtualService的超时时间长于15秒。
如下是ServiceEntry 和VirtualService的样例,定期进行DNS解析和设置response timeout为30秒:
ServiceEntry
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: ext-service-se
spec:
hosts:
- external.service.com
location: MESH_EXTERNAL
ports:
- number: 80
name: service-http
protocol: HTTP
resolution: DNS
VirtualService
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ext-service-vs
spec:
hosts:
- external.service.com
http:
- timeout: 30s
route:
- destination:
host: external.service.com
weight: 100
上述ServiceEntry 默认300秒刷新一次DNS解析,可以通过istio-proxy配置看到如下配置信息:
"dns_refresh_rate": "300s",
"dns_lookup_family": "V4_ONLY",
"load_assignment": {
"cluster_name": "outbound|80||external.service.com",
"endpoints": [
{
"lb_endpoints": [
{
"endpoint": {
"address": {
"socket_address": {
"address": "external.service.com",
"port_value": 80
}
}
},
"load_balancing_weight": 1
可以通过“global.proxy.dnsRefreshRate”参数修改默认DNS刷新频率,但是需要注意的是这是一个全局配置,一旦修改将会影响到整个网格,一定要谨慎修改。
总结
应用接入istio-proxy边车,一个5xx问题意味着有某些原因导致了服务调用出现问题,需要仔细的通过应用监控、上游服务监控、istio-proxy日志和istio配置仔细分析和定位问题。合理的设置ServiceEntry 和VirtualService,服务端的keep-alive链接配置,对于解决http 503和504也是十分重要的。