
深入学习kubernetes联邦
Kubernetes从1.8版本起就声称单集群最多可支持5000个节点和15万个Pod,这个规模对于腰部以下团队来讲已经足够应对业务膨胀。但是总会出于混合云、可扩展性、降低网络延迟或者跨可用区故障隔离等各种各样因素考量去部署多集群。Kubernetes Cluster Federation 又名 KubeFed 或 Federation v2,Federation将使管理多个集群变得简单,打破各个集群边界,使之不再是一个个孤岛。
为什么要kubernetes联邦?
Federation的主要目标之一是能够定义API和API组(即 “一种将规范的 Kubernetes API 资源分配到不同集群的机制”),其中包含联邦任何给定Kubernetes资源所需的基本原则。实现单一集群统一管理多个kubernetes集群的机制。这些集群可以是跨地域的,跨云厂商的或者是用户内部自建集群。Federated Service 的核心是包含一个 Template(Kubernetes服务的定义)、一个 Placement(部署到哪个集群)、一个 Override(在特定集群中的可选变化)和一个 ServiceDNSRecord(指定如何发现它的细节)。 注意:联邦服务必须是 LoadBalancer 类型,以便它可以跨集群发现。
Federation主要解决以下几个问题:
- 跨集群同步资源:Federation 提供了在多个集群中保持资源同步的能力。例如,可以保证同一个 deployment 在多个集群中存在。
- 跨集群服务发现:Federation提供了自动配置DNS服务以及在所有集群后端上进行负载均衡的能力。例如,可以提供一个全局 VIP 或者 DNS 记录,通过它可以访问多个集群后端。
- 跨集群调度:保证服务的稳定性以及可用性。
集群联邦架构
集群联邦需要我们把资源从管理集群同步资源到联邦集群,传播(Propagation)是该项目引入的一个术语,它会将宿主集群中的资源分配到所有的联邦集群中。配置过程如下图所示:
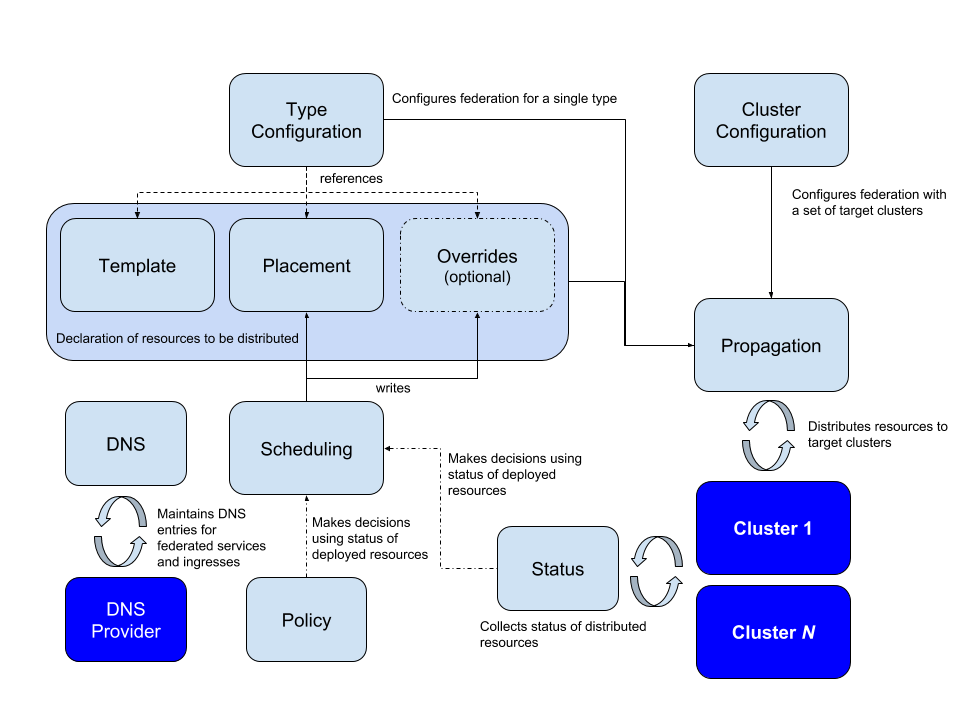 上图中展示了配置集群联邦的过程:
上图中展示了配置集群联邦的过程:
- 配置需要联邦的集群
- 配置需要在集群中传播的 API 资源
- 配置 API 资源如何分配到不同的集群
- 对集群中 DNS 记录注册
这个机制会需要引入以下三个概念:Template、Placement 和 Overrides:
- Template:定义了该资源的一些基本信息,以 Deployment 为例,可能包含部署的容器镜像、环境变量以及实例数等信息。
- Placement:决定该资源需要部署在哪些集群中。
- 覆写原有 Template 中的资源,以满足当前集群的一些特定需求,例如实例数、拉镜像使用的秘钥等与集群有关的属性。
在具体的实现上,kubefed 选择为集群中的所有资源生成对应的联邦资源,例如 Deployment 和对应的 FederatedDeployment。联邦资源中的 spec 字段存储了 Deployment 资源的模板,而 overrides 中定义了资源同步到不同集群时需要做的变更。
kind: FederatedDeployment
...
spec:
...
overrides:
# Apply overrides to cluster1
- clusterName: cluster1
clusterOverrides:
# Set the replicas field to 5
- path: "/spec/replicas"
value: 5
# Set the image of the first container
- path: "/spec/template/spec/containers/0/image"
value: "nginx:1.17.0-alpine"
# Ensure the annotation "foo: bar" exists
- path: "/metadata/annotations"
op: "add"
value:
foo: bar
# Ensure an annotation with key "foo" does not exist
- path: "/metadata/annotations/foo"
op: "remove"
# Adds an argument `-q` at index 0 of the args list
# this will obviously shift the existing arguments, if any
- path: "/spec/template/spec/containers/0/args/0"
op: "add"
value: "-q"
Cluster Configuration
通过 kubefedctl join/unjoin 来加入/删除集群,当成功加入时,会建立一个 KubeFedCluster 组件来储存集群相关信息,如 API Endpoint、CA Bundle 等。这些信息会被用在 KubeFed Controller 存取不同 Kubernetes 集群上,以确保能够建立 Kubernetes API 资源。如下所示:
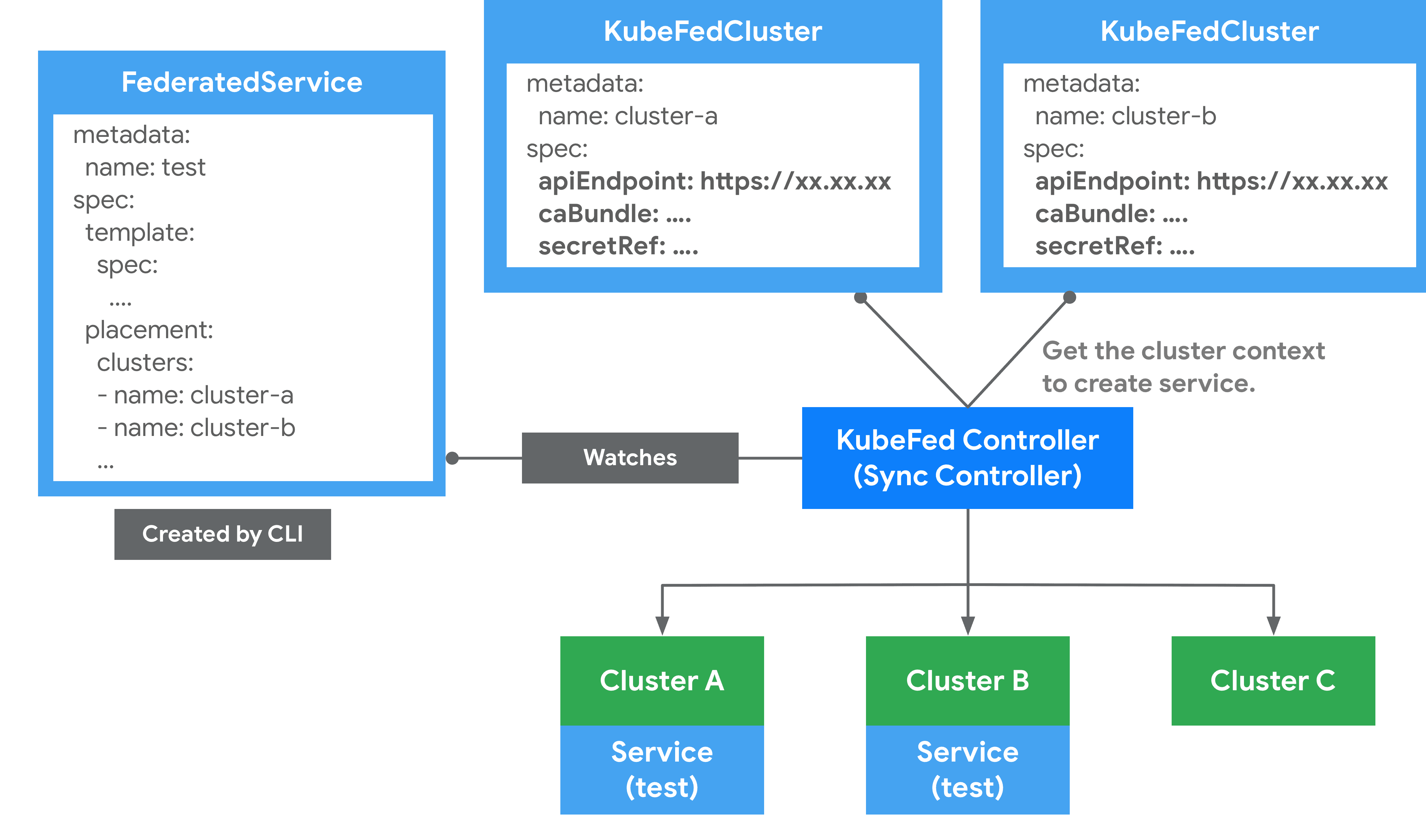 在 Federation 中有两种类型集群:
在 Federation 中有两种类型集群:
- Host : 用于提供 KubeFed API 与控制平面的集群。
- Member : 通过 KubeFed API 注册的集群,并提供相关身份凭证来让 KubeFed Controller 能够存取集群。Host 集群也可以作为 Member 被加入。
联邦服务与跨集群服务发现
Pod 如何发现联邦服务
默认情况下,Kubernetes集群预先配置了集群本地DNS服务器,以及智能构建的DNS搜索路径,它们共同确保了由pod内部运行的软件发出的 myservice、myservice.mynamespace或 some-other-service.other-namespace 等 DNS 查询会自动扩展并正确解析到本地集群中运行的服务的相应 IP。
随着联邦服务和跨集群服务发现的引入,这个概念被扩展到全局覆盖在你的集群联邦中所有集群中运行的Kubernetes服务。为了利用这个扩展的范围,我们需要使用一个稍微不同的DNS名称(例如myservice.mynamespace.myfederation)来解析联邦服务。使用不同的 DNS名称还可以避免现有的应用意外地穿越区域网络而会产生不必要的网络延迟。
例如使用一个名为 nginx 的服务。
在 us-central1-a 可用区的集群中的一个 pod 需要联系我们的 nginx 服务。它现在可以使用服务的联邦 DNS 名,即 nginx.mynamespace.myfederation ,而不是使用服务的传统集群本地 DNS 名(即 nginx.mynamespace 自动扩展为 nginx.mynamespace.svc.cluster.local)。这将被自动扩展并解析到离我的 nginx 服务最近的健康 shard。如果本地集群中存在一个健康的 shard,那么该服务的集群本地 IP 地址将被返回(通过集群本地 DNS)。这完全等同于非联邦服务解析。
如果服务在本地集群中不存在(或者存在但没有健康的后端 pod),DNS 查询会自动扩展到 nginx.mynamespace.myfederation.svc.us-central1-a.example.com。在幕后,这可以找到离我们的可用区最近的一个 shard 的外部 IP。这个扩展是由集群本地 DNS 服务器自动执行的,它返回相关的 CNAME 记录。这就导致了对 DNS 记录的层次结构的遍历,并最终找到附近联邦服务的一个外部 IP。
也可以通过明确指定适当的 DNS 名称,而不是依赖自动的DNS扩展,将目标锁定在 pod 本地以外的可用性区域和地区的服务 shard。例如,nginx.mynamespace.myfederation.svc.europe-west1.example.com 将解析到欧洲所有当前健康的服务 shard,即使发布查询的 pod 位于美国,也不管美国是否有健康的服务 shard,这对远程监控和其他类似的应用很有用。
从联邦集群之外的其他客户端发现联邦服务
对于外部客户端,目前还不能实现所述自动 DNS 扩展。外部客户需要指定联邦服务的一个完全限定的 DNS 名称,无论是区域、可用区还是全局名称。
Type Configuration
定义了哪些 Kubernetes API 资源要被用于联邦管理。比如说想将 ConfigMap 资源通过联邦机制建立在不同集群上时,就必须先在 Federation Host 集群中,通过 CRD 建立新资源 FederatedConfigMap,接着再建立名称为 configmaps 的 Type configuration(FederatedTypeConfig)资源,然后描述 ConfigMap 要被 FederatedConfigMap 所管理,这样 KubeFed Controllers 才能知道如何建立 Federated 资源。
一个 Federated资源一般都会具备三个主要功能,这些信息能够在spec中由使用者自行定义,如下范例:
apiVersion: types.kubefed.k8s.io/v1beta1
kind: FederatedDeployment
metadata:
name: test-deployment
namespace: test-namespace
spec:
template:
metadata:
labels:
app: nginx
spec:
...
placement:
clusters:
- name: cluster2
- name: cluster1
overrides:
- clusterName: cluster2
clusterOverrides:
- path: spec.replicas
value: 5
- Placement:定义 Federated 资源要分散到哪些集群上,若没有该文件,则不会分散到任何集群中。如 FederatedDeployment 中的 spec.placement 定义了两个集群时,这些集群将被同步建立相同的 Deployment。另外也支持用 spec.placement.clusterSelector 的方式来选择要放置的集群。
- Override:定义修改指定集群的 Federated 资源中的 spec.template 内容。如部署 FederatedDeployment 到不同公有云上的集群时,就能通过 spec.overrides 来调整 Volume 或副本数。
跨集群调度
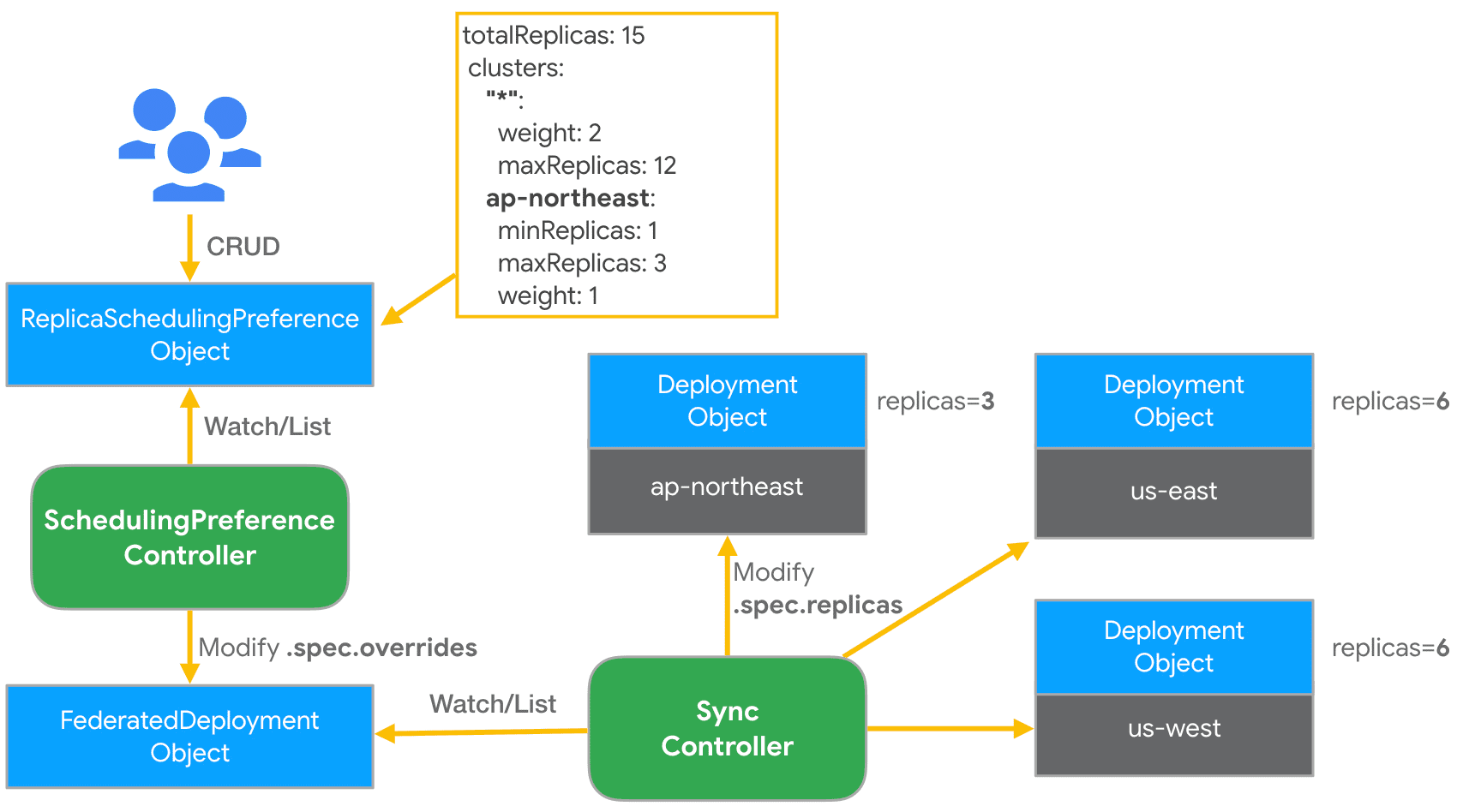
KubeFed 提供了一种自动化机制来将工作负载实例分散到不同的集群中,这能够基于总副本数与集群的定义策略来将 Deployment 或 ReplicaSet资源进行编排。编排策略是通过建立 ReplicaSchedulingPreference(RSP)文件,再由 KubeFed RSP Controller 监听与撷取RSP内容来将工作负载实例建立到指定的集群上。这是基于用户给出的高级用户偏好。这些偏好包括加权分布的语义和分布副本的限制(最小和最大)。这些还包括允许动态重新分配副本的语义,以防某些副本 Pod 仍然没有被调度到某些集群上,例如由于该集群资源不足。
以下为一个RSP范例,假设有三个集群被联邦,名称分别为 ap-northeast、us-east 与 us-west。
apiVersion: scheduling.kubefed.k8s.io/v1alpha1
kind: ReplicaSchedulingPreference
metadata:
name: test-deployment
namespace: test-ns
spec:
targetKind: FederatedDeployment
totalReplicas: 15
clusters:
"*":
weight: 2
maxReplicas: 12
ap-northeast:
minReplicas: 1
maxReplicas: 3
weight: 1
整个过程如下:
跨集群服务发现(Multi-cluster DNS)
KubeFed 提供了一组 API 资源,以及 Controllers 来实现跨集群Service/Ingress 的 DNS records自动产生机制,并结合ExternalDNS 来同步更新至 DNS 服务供应商。
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: Domain
metadata:
name: test
namespace: kube-federation-system
domain: k8s.example.com
---
apiVersion: multiclusterdns.kubefed.k8s.io/v1alpha1
kind: ServiceDNSRecord
metadata:
name: nginx
namespace: development
spec:
domainRef: test
recordTTL: 300
首先假设已建立一个名称为 nginx 的 FederatedDeployment,然后放到 development namespace 中,并且也建立了对应的 FederatedService 提供 LoadBalancer。这时当建立上述 Domain 与 ServiceDNSRecord 后,KubeFed 的 Service DNS Controller 会依据 ServiceDNSRecord 文件内容,去收集不同集群的 Service 信息,并将这些信息更新至 ServiceDNSRecord 状态中,接着 DNS Endpoint Controller 会依据该 ServiceDNSRecord 的状态内容,建立一个 DNSEndpoint 文件,并产生 DNS records 资源,最后再由 ExternalDNS 来同步更新 DNS records 至 DNS 供应商。下图是 Service DNS 建立的架构。
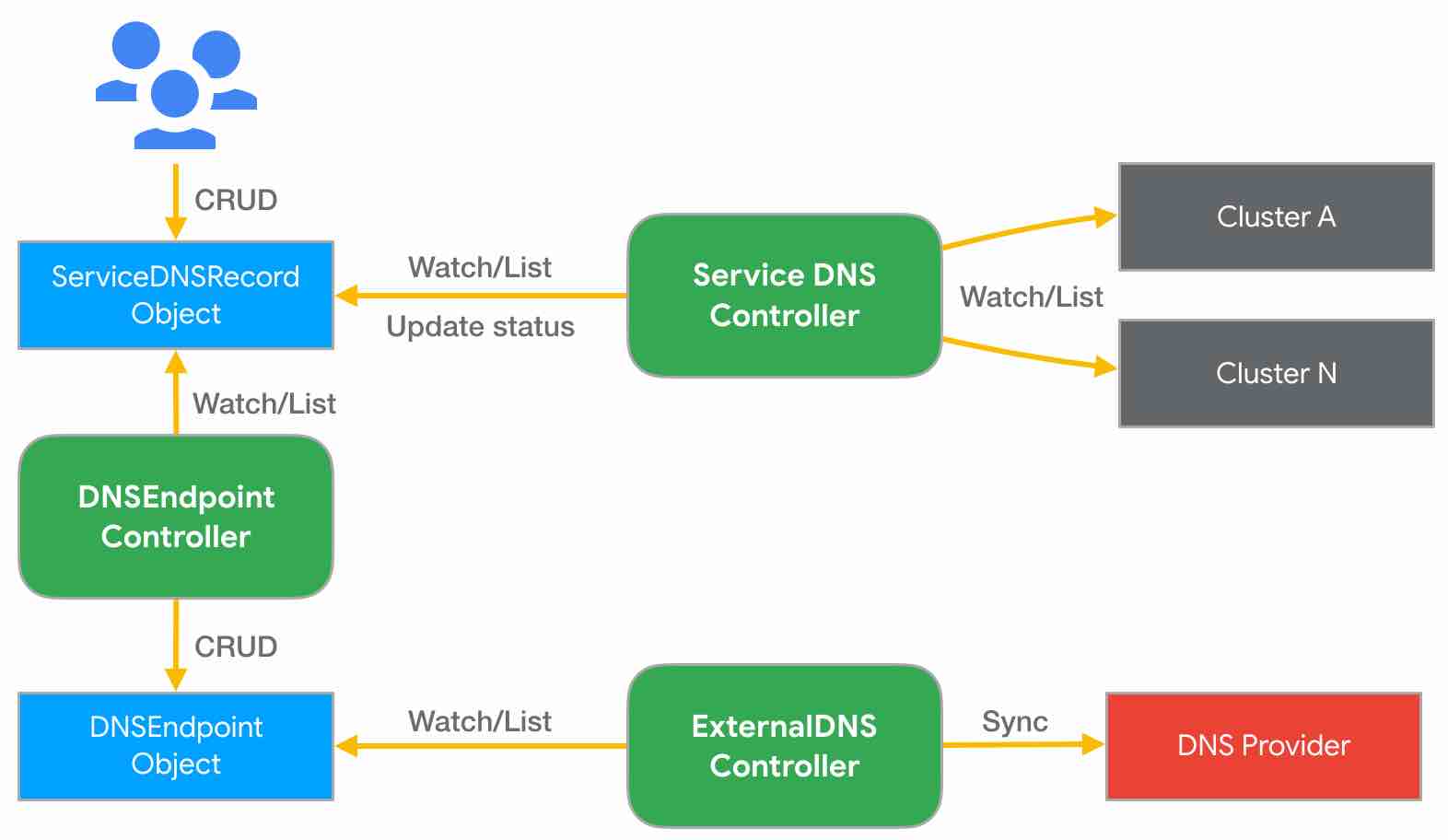 若是 Ingress 的话,会由 IngressDNSRecord 文件取代,并由 Ingress DNS Controller 收集信息。
若是 Ingress 的话,会由 IngressDNSRecord 文件取代,并由 Ingress DNS Controller 收集信息。
Federation本身当然也有他的缺点:
- 增加网络带宽和成本:federation 控制平面监控所有集群以确保当前状态符合预期。如果集群在云服务提供商的不同区域或者不同的云服务提供商上运行时,这将导致明显的网络成本增加。
- 减少跨集群隔离:federation 控制平面中的故障可能影响所有集群。通过在federation中实现最少的逻辑可以缓解这种情况。只要有可能,它就将尽力把工作委托给 kubernetes集群中的控制平面。这种设计和实现在安全性及避免多集群停止运行上也是错误的。