
分布式系统中亚稳定失败状态
这篇文章的初衷,是记录拜读由Nathan Bronson, Aleksey Charapko, Abutalib Aghayev, and Timothy Zhu共同发表的论文Metastable Failures in Distributed Systems的收获,这篇论文描述了一个在大规模分布式系统中很常见的失败场景:亚稳定失败(metastable failures),它们为什么通常在高负载分布式系统中发生,以及解决问题的思路框架:如何识别和从亚稳定失败中恢复,甚至如何避免发生亚稳定失败。
现实世界中的亚稳定失败
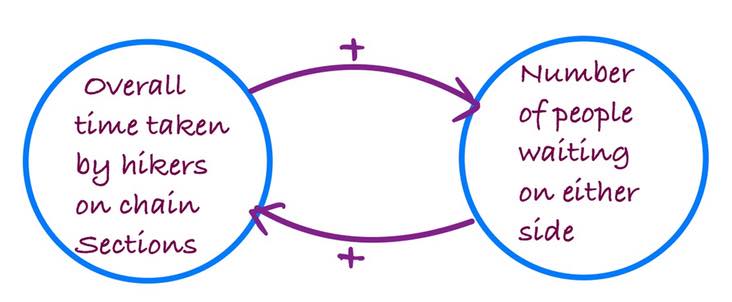
下图是某个公园中非常著名的徒步路线中非常关键的一部分:两座山之间一段狭长的山脊,在两座山之间徒步,只有扶着铁链穿过这段山梁才能保证安全。可以假想这段铁链就是一个分布式系统。
 当公园不对徒步者人数做限制时,就有可能引起人群拥挤以至于长时间在起点等待去尝试减低负载。你可以想象一下”系统“经历了以下的状态转换。
当公园不对徒步者人数做限制时,就有可能引起人群拥挤以至于长时间在起点等待去尝试减低负载。你可以想象一下”系统“经历了以下的状态转换。
-
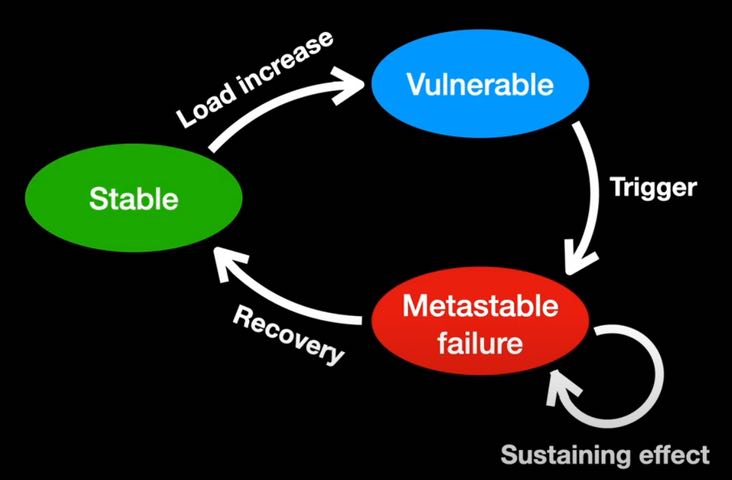
稳定状态(Stable state) 当人群低于某个安全阈值时,任何一个风险因素(例如:缓慢通过铁链的徒步者)都可能引起降速,但是系统仍然能够自愈。
-
脆弱状态(Vulnerable state) 拥挤人群的数量持续增加超过了某个阈值,对于每段铁链的竞争也会增加 —— 下山的人必须要等待上山的人通过,或者干脆冒险不使用铁链而绕过他们。同样,上山的人也必须等待下山的人通过。当这种模式发生时,只要拥挤人群的数量低于某个阈值,系统仍然是可以工作的,但它现在是非常脆弱的,可能变成不可自愈的失败状态。
-
亚稳定失败状态(Metastable Failure State) 当系统处于脆弱状态,某些风险因素可能导致情况恶化。想象一下,一组徒步者需要花费更长的时间通过铁链,这将会使其他上山和下山的人速度降下来。越来越多的人等待,导致在铁链两端和身在其中的剩余空间越来越狭窄,进而导致人们需要更多的时间通过,进一步导致更多的人等待…情况循环恶化 —— 进入亚稳定失败状态。
 保持系统处于亚稳定失败状态的正反馈循环
保持系统处于亚稳定失败状态的正反馈循环
由于这个自续的反馈循环,系统将保持在这个状态,即使移除最初的诱发风险因素。为了恢复,需要采取其他的措施,例如将负载降低到特定阈值以下。
亚稳定失败定义
关于亚稳定失败的定义论文中描述如下
亚稳定失败发生在对于负载来源没有控制的开放系统中,一个风险因素导致系统进入一个糟糕的状态,并且会持续存在甚至风险因素被移除。在这个状态系统的效率通常会很低,并且会产生持续影响——通常使工作负载放大或者整体效率降低——阻止系统从这个糟糕的状态中恢复。 Metastable failures occur in open systems with an uncontrolled source of load where a trigger causes the system to enter a bad state that persists even when the trigger is removed. In this state the goodput (i.e., throughput of useful work) is unusably low, and there is a sustaining effect — often involving work amplification or decreased overall efficiency — that prevents the system from leaving the bad state.
 如果这样,那么为什么不总是运行在稳定状态?诚如,在许多系统中高效的资源利用是非常重要的,所以许多系统选择运行在脆弱状态而不是稳定状态,已获得更高的效率。
当系统处于亚稳定失败状态,系统不会自愈,想要恢复需要采取重要措施,例如降低负载。
如果这样,那么为什么不总是运行在稳定状态?诚如,在许多系统中高效的资源利用是非常重要的,所以许多系统选择运行在脆弱状态而不是稳定状态,已获得更高的效率。
当系统处于亚稳定失败状态,系统不会自愈,想要恢复需要采取重要措施,例如降低负载。
问题的症结:正反馈循环
正反馈循环是亚稳定失败发生的根源。例如,在维基百科中给出了这样例子:
A生产了更多的B,B反过来又生产了更多的A
又例如,人群狂奔:假设美国纽约街道上正在进行独立日游行,突然有人开始奔跑(A)导致周围人群开始恐慌(B),更多的人开始奔跑(A)更多的人开始恐慌(B)更多人开始奔跑。。。最终导致人群狂奔(也许现在还没有枪响)。
可能有很多不同风险因素能够将系统带到亚稳定失败状态。但是,能够将系统保持在这种状态甚至在移除该风险因素之后仍然不能发生变化的,是自我维持的反馈循环。
亚稳定失败的例子
- 重试导致工作负载放大 假设我们有一个web服务端承接客户端请求,持久层数据库服务的性能为300 QPS和100毫秒的延迟,服务端有一个原生的重试机制:每次请求失败都会立即重试。
只要服务端入流量的请求负载低于150QPS,即使发生重试,当一个风险因素(例如短暂的网络故障)发生并导致请求积压它依然可以自愈。这就是“健康”状态。
然而,当负载超过150QPS,系统将进入“脆弱”状态——假设负载为280QPS,当处于这种状态时系统依然还是可以工作的。现在,如果在服务端和数据库直接有10S的网络断开,数据库将面对流量的陡增(原始流量+重试),这将增加请求延迟进而导致更多的重试,进一步增加请求延。导致一个自续的循环。
- 为happy path所做的优化工作 任何为happy path优化而做出的努力都更可能进入亚稳定失败状态。假设上边同样的系统但是有一个缓存服务以降低数据库服务的调用次数。如果缓存命中率是90%,那么服务端在脆弱状态下能够处理3000QPS(服务端处理300QPS)的负载。但是如果缓存服务由于某些原因需要重启,那么我们将面临一个问题:它将是完美进入到亚稳定失败状态的诱因。论文中将3000QPS称为表面容量(advertised capacity)(系统将处于脆弱状态的上限),而300QPS是隐含容量(hidden capacity)(系统能够自愈的上限)。
以上展示的工作负载放大在许多大规模请求中断时是非常普遍的。但是研究的案例我发现最有感兴趣的是“连接不平衡”,由于使用MRU策略,两个系统之间的连接中最慢的连接总是被选择。
如何处理已知的亚稳定失败
在论文中描述了一些预防已知亚稳定失败的技术:
-
专注于风险因素的持续反馈循环 去定位一个亚稳定失败模式,专注于弱化正反馈循环,这涉及到工作负载放大,而不是针对风险因素打地鼠。
-
识别最强反馈循环 理解哪里是产生工作负载放大最大的实例,然后为它定义一个最大值。大体上,识别最强反馈循环并且不要追逐每一个反馈循环。 如何识别他们呢?压力测试是一个方式。但是挑战是越大规模的服务,反馈循环越强,所以第一次在大规模服务中会发现很多问题。 因此,你能做的事情是识别被风险因素影响的特征指标:例如,上述实例中的重试率。通过这样,你可以理解稳定、脆弱和亚稳定失败状态的边界。
-
弱化反馈循环 论文描述了一些弱化反馈循环的方法。例如包括削弱负载和熔断机制。主要的挑战是这将由客户端来决策何时重试和故障转移,但是客户端通常没有全局信息(并且试图去提供这种服务本身也可能导致失败)。区分短暂的负载峰值和持续性的过载是非常重要的,你可能需要有指标帮助你去准确的识别这两者。
论文为组织激励提供了一个很好的示例,奖励正确的优化措施(例如优先降低资源使用率)而不是在更有可能导致亚稳定失败的happy path上的优化。
总结
希望通过以上的讨论能有所收益,希望下次在发现”一些列的请求失败“、”死亡螺旋“、”彻底失败“等等,你可以使用这些作为一个思考框架或者通用语言去理解他。论文中还有许多其他的示例和思考,感兴趣可以阅读一下论文原文。
原文地址:Metastable Failures in Distributed Systems: What Causes Them and 3 Things You can do to Tame Them